Neo4j简介
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。
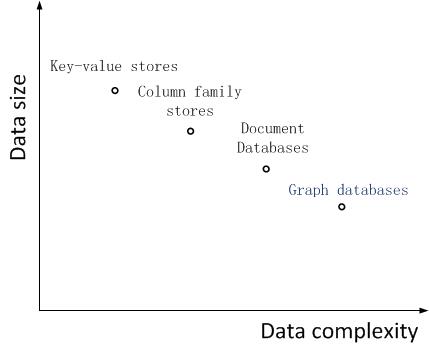
下面一张图说明,相比于其他NoSQL,图数据库存放的数据规模有所下降,但是更能够表达复杂的数据。
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j分三个版本:社区版(community)、高级版(advanced)和企业版(enterprise)。社区版是基础,本文主要对其作出介绍,它使用的是GPLv3协议,这意味着修改和使用其代码都需要开源,但是这是建立在软件分发的基础上,如果使用Neo4j作为服务提供,而不分发软件,则不需要开源。这实际上是GPL协议本身的缺陷。高级版和企业版建立在社区版的基础上,但多出一些高级特性。高级版包括一些高级监控特性,而企业版则包括在线备份、高可用集群以及高级监控特性。要注意它们使用了AGPLv3协议,也就是说,除非获得商业授权,否则无论以何种方式修改或者使用Neo4j,都需要开源。
接下来就从Neo4j的几个主要特性出发,结合代码逐一作出介绍。它们包括:数据模型、索引、事务、遍历和查询、以及图算法。
