Dpark源码剖析一(概述)
Dpark/Spark中最重要的核心就是RDD(弹性分布式数据集,Resilient Distributed Datasets),为了给今后的分析打下基础,这篇文章首先会解释RDD相关的重要概念。接着会简单介绍dpark中的另外两个重要核心Accumulator(累加器)和Broadcast(广播变量),关于这两者这里只做简单介绍,我们后面会对分别单独对源码做分析。
Spark不光是用函数式语言scala写的,它也到处体现着函数式语言的特性。Dpark当然也继承了这些特性,这个我们接下来会逐一分析。类似于spark,dpark也是master-slave架构的,但不同于spark,dpark中仅提供了三种运行方式:本地模式(local,单进程)、多进程模式(实际上也是单机)以及mesos模式(使用mesos来调度达到分布式计算的目的)。
RDD
首先需要说明的是弹性分布式数据集(RDD),dpark和最新的spark这部分已经有所不同,主要体现在对内存和磁盘抽象上,下面包括以后的文章都会以dpark为准。
RDD听起来很玄乎,其实很简单。它是一个抽象,本质上表示大量的可迭代数据,这些数据可以直接存在于内存中,也可以延迟读取。但是数据量太大,怎么办?尝试把数据分成各个分片(split),每个分片对应着一部分数据,这样可以将一个RDD分开来存取和执行运算。RDD是不可变的,这符合函数式编程中的不可变数据的特性,不要小看这个特性,它其实在分布式计算的环境中非常重要,能简化分布式环境下的计算。
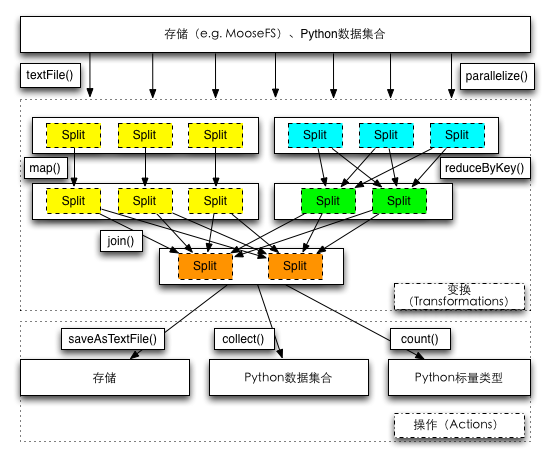
在dpark中,一个RDD中的元素通常来说有两种:一种是单一的值,还有一种是key和value组成的对(元组表达,(key, value))。如上图所示,RDD的数据来源也通常有两种:一种是Python数据集合(如list等),也可以是分布式文件系统(本地文件系统亦可,这种情况可以用在本地模式和多进程模式)。
我们来看看RDD的初始化以及重要的函数。
class Split(object):
def __init__(self, idx):
self.index = idx
class RDD(object):
def __init__(self, ctx):
self.ctx = ctx
self.id = RDD.newId()
self._splits = []
self.dependencies = []
self.aggregator = None
self._partitioner = None
self.shouldCache = False
self.snapshot_path = None
ctx.init()
self.err = ctx.options.err
self.mem = ctx.options.mem
@cached
def __getstate__(self):
d = dict(self.__dict__)
d.pop('dependencies', None)
d.pop('_splits', None)
d.pop('ctx', None)
return d
def _preferredLocations(self, split):
return []
def preferredLocations(self, split):
if self.shouldCache:
locs = env.cacheTracker.getCachedLocs(self.id, split.index)
if locs:
return locs
return self._preferredLocations(split)
def cache(self):
self.shouldCache = True
self._pickle_cache = None # clear pickle cache
return self
def snapshot(self, path=None):
if path is None:
path = self.ctx.options.snapshot_dir
if path:
ident = '%d_%x' % (self.id, hash(str(self)))
path = os.path.join(path, ident)
if not os.path.exists(path):
try: os.makedirs(path)
except OSError: pass
self.snapshot_path = path
return self
def compute(self, split):
raise NotImplementedError
def iterator(self, split):
if self.snapshot_path:
p = os.path.join(self.snapshot_path, str(split.index))
if os.path.exists(p):
v = cPickle.loads(open(p).read())
else:
v = list(self.compute(split))
with open(p, 'w') as f:
f.write(cPickle.dumps(v))
return v
if self.shouldCache:
return env.cacheTracker.getOrCompute(self, split)
else:
return self.compute(split)
这里Split类非常简单,只有个索引号index,表示是第几个分片。RDD的属性中的_splits指的是该RDD的所有分片。Split及其子类的作用是,告诉RDD该分片该如何计算,是读取分布式文件系统中的数据呢,还是读取内存中的列表的某一部分?Split中可以存放数据,也可以只提供读取数据需要的参数。
函数式编程中函数是一等公民,RDD也拥有大量的函数来进行计算。这些计算可以分为两类:变换(Transformations)和操作(Actions)。变换比如说map函数,它的参数是一个函数func,我们对于RDD中的每个元素,调用func函数将其变为另一个元素,这样就组成了新的RDD。类似的这种计算过程不是立即执行的,可能经历过多个变换后,等到需要将结果返回主程序时才执行,这个时候,从一个RDD到另一个RDD就是一个变换的过程。对于操作来说,执行的时候,相关的计算会立刻执行,并将结果返回(比如说reduce、collect等等)。计算的结果可以直接写入存储(比如调用saveAsTextFile),可以转化为Python集合数据(比如collect方法,返回包含全部数据的列表),也可以返回标量的结果(比如count方法,返回所有元素的个数)。
恰好是由于RDD的不可变性,在变换的过程中,我们只需记录下足够的信息,这时就可以在真正需要数据时执行计算。这种惰性计算的特点使得dpark/spark的计算相当高效。
那么这些信息包括什么呢?RDD的dependencies就是之一,它记录下了当前的RDD是从哪个或者哪些RDD得到的,这些依赖是Dependency类或者子类的实例,这在dpark中被称为血统(lineage),听起来很高大上吧?通过这些依赖,你就能得到一个RDD的父母或者祖先有哪些。关于具体的依赖关系,我们会在接下来文章中结合RDD的各种变换来详细说明。
这里需要先提下依赖的大致分类。dpark中,dependency可以分为两大类,窄依赖和宽依赖。什么叫窄依赖?非宽依赖是也,你会说,这不废话么?那就让我们先看看什么叫宽依赖。对于当前的RDD的一个分片,它的数据可能来自依赖RDD的任意分片,这就叫宽依赖。比如说对于存放键值对的依赖RDD,我们执行groupByKey操作,也就是把key相同的值都聚合起来,这时候,key可能存在于依赖RDD的任意分片,这就叫宽依赖。因此,窄依赖就显而易见了,对于当前RDD的一个分片,它只可能源自于依赖RDD的有限个分片,这就是窄依赖,比如说map操作,当前RDD的某分片中的每个元素就是由依赖RDD的对应的分片数据算来的。之所以这里先提下宽依赖和窄依赖,对后面的理解大有裨益。
RDD类中包含了一个compute接口,它的参数是一个分片。对于不同的RDD的子类,这个方法提供了给定分片的数据的生成方法。但是在这个接口外还包装了一个iterator方法,这才是内部运算时真正调用的方法,为什么呢?这里涉及到了snapshot和cache。下面逐一说明。
首先是snapshot。RDD中通过snapshot方法,将参数snapshot_path设置为创建的路径。而在iterator调用时,会根据snapshot_path是否为空来判断是否做snapshot。snapshot时,需要提供所有运算机器能够访问的共享的文件路径(包括分布式文件系统),这样,在iterator时首先判断是否需要做snapshot,如果要则判断对应的数据文件是否在,如果不在,则先创建,再将compute计算后的结果序列化后直接写入文件;如果存在,则直接读出并反序列化。
cache和snapshot的区别在于,cache是写入内存(在本地模式下);或者本地文件系统(其他模式),并让master记录下在那个机器做的cache以及路径(这么说不准确,但是可以这么理解)。这样就不需要一个共享的文件路径,同样在iterator调用的时候可以先从cache中读出(这里可能涉及到远程读取,因为写入的地方可能不在本地)。这里的过程会复杂得多,我们会在以后专门讲解,同学们只要留下印象即可。
另外一对重要的方法是_preferredLocations和preferredLocations(就一个下划线的区别),它们都表示该RDD的某个分片计算时期望执行的地址(在哪个机器上执行)。首先我们说说公有方法preferredLocations,首先如果一个RDD的分片做过cache,那么当然希望在有缓存的机器上执行,否则就返回私有方法_preferredLocations的结果。对于这个私有方法来说,具体的RDD子类会覆盖这个方法。比如说,一个RDD从分布式文件系统读取数据,我们知道,分布式文件中的文件以块的形式放在不同的机器上,那么我们当然希望这个RDD期望运行的地址是在读取块所在的机器上,这样能减少网络的开销;又比如,有着某个RDD的某个分片依赖于另一个RDD的一个分片,前者更倾向于在后者机器上执行计算,否则还需要进行一次拷贝操作。
值得一提的是RDD类的__getstate__方法,这个方法告诉序列化模块应该要序列化哪些属性。ctx表示表示程序运行入口的上下文,序列化不需要ok。但是为什么不序列化依赖和分片呢?这个留到后面解答。
Accumulator和Broadcast(共享变量)
除了RDD,dpark还提供了两种集群各机器间可以共享的变量。一个是累加器(Accumulator),一种在运行时只可以进行累加操作的变量;还有一个是广播变量(Broadcast),它用来将一个通常是较大的变量发布到所有的计算节点,这样避免了序列化和反序列化的开销。这里一笔带过,以后详述。











今天,你和我们分享一些新东西,因为我先不了解它。我希望我能尽快使用它来使我的网站快速完成。