Neo4j简介
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。
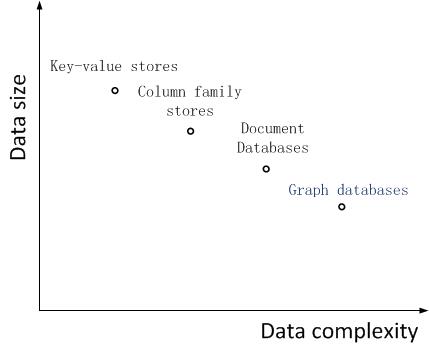
下面一张图说明,相比于其他NoSQL,图数据库存放的数据规模有所下降,但是更能够表达复杂的数据。
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j分三个版本:社区版(community)、高级版(advanced)和企业版(enterprise)。社区版是基础,本文主要对其作出介绍,它使用的是GPLv3协议,这意味着修改和使用其代码都需要开源,但是这是建立在软件分发的基础上,如果使用Neo4j作为服务提供,而不分发软件,则不需要开源。这实际上是GPL协议本身的缺陷。高级版和企业版建立在社区版的基础上,但多出一些高级特性。高级版包括一些高级监控特性,而企业版则包括在线备份、高可用集群以及高级监控特性。要注意它们使用了AGPLv3协议,也就是说,除非获得商业授权,否则无论以何种方式修改或者使用Neo4j,都需要开源。
接下来就从Neo4j的几个主要特性出发,结合代码逐一作出介绍。它们包括:数据模型、索引、事务、遍历和查询、以及图算法。
数据模型
Neo4j被称为property graph,除了顶点(Node)和边(Relationship,其包含一个类型),还有一种重要的部分——属性。无论是顶点还是边,都可以有任意多的属性。属性的存放类似于一个hashmap,key为一个字符串,而value必须是Java基本类型、或者是基本类型数组,比如说String、int或者int[]都是合法的。
接下来本文都会围绕下图进行举例。

可以看到Thomas Anderson这个Node有age和name的property,其指向Trinity的relationship边类型为KNOWS,有age的属性。
要生成上图所示数据,首先可以定义所有边的类型:
import org.neo4j.graphdb.RelationshipType;
private static enum RelTypes implements RelationshipType {
NEO_NODE,
KNOWS,
CODED_BY
}
接下来的代码创建了起始顶点和“Thomas Anderson”顶点,并创建了它们之间的边。其余数据生成类似。
import org.neo4j.graphdb.Node; Node startNode = graphDB.createNode(); Node thomas = graphDB.createNode(); thomas.setProperty( "name", "Thomas Anderson" ); thomas.setProperty( "age", 29 ); startNode.createRelationshipTo( thomas, RelTypes.NEO_NODE );
索引
Neo4j支持索引,其内部实际上通过Lucene实现。现在可以创建一个索引叫nodes,来索引所有拥有name属性的顶点,这样我们就可以查询名字为“Thomas Anderson”的节点了。以下代码创建了这个索引,并索引了“Thomas Anderson”顶点,并通过名字得到了它。
import org.neo4j.graphdb.index.Index;
Index<Node> nodeIndex = graphDB.index().forNodes("nodes");
// 将thomas顶点的name属性添加到索引
nodeIndex.add(thomas, "name", thomas.getProperty("name"));
// 通过thomas的name得到顶点
Node thomas = nodeIndex.get("name", "Thomas Anderson").getSingle();
事务
Neo4j完整支持事务,即满足ACID性质。示例代码如下:
import org.neo4j.graphdb.Transaction;
Transaction tx = graphDB.beginTx();
try {
// do sth...
tx.success();
}
finally {
tx.finish();
}
遍历和查询
遍历是图数据库中的主要查询方式,所以遍历是图数据中相当关键的一个概念。可以用两种方式来进行遍历查询:第一种是直接编写Java代码,使用Neo4j提供的traversal框架;第二种方式是使用Neo4j提供的描述型查询语言,Cypher。第一种方式例子如下:
import org.neo4j.graphdb.traversal.Evaluators;
import org.neo4j.graphdb.traversal.Traverser;
import org.neo4j.graphdb.traversal.TraversalDescription;
import org.neo4j.kernel.Traversal;
public Traverser getFriends(final Node person) {
TraversalDescription td = Traversal.description()
// 这里是广度优先,也可以定义为深度优先遍历
.breadthFirst()
// 这里定义边类型必须为KNOWS,且必须都为出边
.relationships(RelTypes.KNOWS, Direction.OUTGOING)
// 排除开始顶点
.evaluator(Evaluators.excludeStartPosition());
return td.traverse(person);
}
这里得到了Traverser对象后并没有立即执行遍历,而是在真正迭代结果时才进行延迟查询。以下的代码打印出一个顶点的所有朋友以及朋友的朋友。
import org.neo4j.graphdb.Path;
public void printNodeFriends(Node node) {
int friendsNumbers = 0;
System.out.println(node.getProperty(PRIMARY_KEY) + "'s friends:");
for(Path friendPath: getFriends(node)) {
System.out.println("At depth " + friendPath.length() + " => "
+ friendPath.endNode().getProperty(PRIMARY_KEY));
friendsNumbers++;
}
System.out.println("Number of friends found: " + friendsNumbers);
}
输出结果为:
Thomas Anderson's friends:
At depth 1 => Trinity
At depth 1 => Morpheus
At depth 2 => Cypher
At depth 3 => Agent Smith
Number of friends found: 4
关于traversal框架,请参考官方文档。
第二种方法Cypher则直观得多,它是一种描述型的语言。下面是达到同样目标的Cypher命令。
start n=node:nodes(name="Thomas Anderson") match n-[:KNOWS*..]->f return distinct f, f.name
简单做个说明。start说明从n节点开始,它通过查询nodes索引得到。match主要用来匹配图中顶点和边的关系,这里n和f顶点之前的relationship通过方括号表达,“:KNOWS”说明了边类型,“*..”表示可以有任意多的边,如果只要求有两条,则是[:KNOWS*2]。注意到这里的箭头表示是出边方向。return返回结果,distinct去除了重复访问到的顶点。可以看到还是很直观的。
查询结果如下:
+-----------------------------------------------------------------------------------+
| f | f.name |
+-----------------------------------------------------------------------------------+
| Node[4]{name:"Morpheus",rank:"Captain",occupation:"Total badass"} | "Morpheus" |
| Node[5]{name:"Cypher",last name:"Reagan"} | "Cypher" |
| Node[6]{name:"Agent Smith",version:"1.0b",language:"C++"} | "Agent Smith" |
| Node[3]{name:"Trinity"} | "Trinity" |
+-----------------------------------------------------------------------------------+
4 rows
289 ms
不过,Cypher语言不能定义查询是按照深度优先还是广度优先遍历。Cypher更多用法,可以参考官方文档。
图算法
Neo4j实现的三种图算法:最短路径、Dijkstra算法以及A*算法。下面是最短路径算法的简单例子:
import org.neo4j.graphalgo.PathFinder;
import org.neo4j.graphalgo.GraphAlgoFactory;
public Iterable<Path> findShortestPath(Node node1, Node node2) {
PathFinder<Path> finder = GraphAlgoFactory.shortestPath(
Traversal.expanderForTypes(RelTypes.KNOWS, Direction.OUTGOING), 5);
Iterable<Path> paths = finder.findAllPaths(node1, node2);
return paths;
}
public void printShortestPaths() {
Node node1 = nodeIndex.get(PRIMARY_KEY, "Thomas Anderson").getSingle();
Node node2 = nodeIndex.get(PRIMARY_KEY, "Agent Smith").getSingle();
for(Path shortestPath: findShortestPath(node1, node2)) {
System.out.println(shortestPath.toString());
}
}
图算法的更多信息,可以参考官方文档。
总结
本文对Neo4j做了简单的介绍,更多信息可以参考Neo4j的官方网站。
在社交网络呈爆炸性发展的今天,随着knowledge graph(知识图谱)技术的兴起,相信图数据库能够扮演越来越重要的角色。
本文使用的完整代码,可以在这里下载。










不错啊。学习了。
看到满满的代码我就蛋碎了一地啊~
最近在学习使用这个,想应用到项目中,楼主写的很好,学习了
楼主,如果不是这么多标签的数据,仅仅是就是一般数据1到20万,节点名字就是数字,
然后比如1链接3,这样的txt数据文件。neo4j可以用吗?
这样做为啥不行
int[] newnode=new int[10];
for(int i=0; i<newnode.length; i++){
Node newnode[i]=db.createNode();
}
newnode[1].createRelationshipTo(newnode[2], Rels.KNOWS );
现在不用阿里云了?
访问速度好慢\n 显示googleapp
.
没有,还是阿里云,可能用到一些google服务被墙了,比较无奈。
具体显示哪个google app?
好像最近比较慢,以前好像还好, 一开始connecting.... 和 waiting for api.google.com 停的时间比较长,你的后台文章编辑发布用的是什么
google的东西被墙了,所以api.google.com什么的会很慢。
整个都是django呀,后台是django admin编辑发布的。
请问下,我再使用代码时发生“ExecutionEngine engine = new ExecutionEngine(graphDB)”没有定义的问题,请问怎么回事?谢谢!
想学习下,可是程序没能跑起来。。。它是怎么连接neo4j的?
最好能补充一下main函数。
很痛苦,年底有一个活动关于Neo4j数据库答辩的,要从同类组件对比、组件的技术架构、组件实现原理、组件参数含义及推荐值、常见问题及注意事项、常见应用场景;其他还好,就是这个“组件实现原理”、“组件参数含义及推荐值、常见问题及注意事项”根本不知道咋入手写
请问,这篇文章的代码,使用了什么 maven 依赖?
给作者留言
关于作者
残阳似血(@秦续业),程序猿一枚,把梦想揣进口袋的挨踢工作者。现加入阿里云,研究僧毕业于上海交通大学软件学院ADC实验室。熟悉分布式数据分析(DataFrame并行化框架)、基于图模型的分布式数据库和并行计算、Dpark/Spark以及Python web开发(Django、tornado)等。
博客分类
搜索
点击排行
标签云
扫描访问
主题
残阳似血的微博
登录