在数据库中存储层级结构
本文参考自这篇文章。文章是2003年的,但是现在来看仍然有着实际意义。
层级结构,也叫树形结构。在实际应用中,你经常需要保存层级结构到数据库中。比如说:你的网站上的目录。不过,除非使用类XML的数据库,通用的关系数据库很难做到这点。
对于树形数据的存储有很多种方案。主要的方法有两种:邻接表模型,以及修改过的前序遍历算法。本文将会讨论这两种方法的实现。这里的例子沿用参考文章中的例子,原文使用的PHP,这里将会用Java替代。(本例使用Mysql数据库,Java如何连接Mysql,见备注一。)文中使用虚拟的在线食品商店作例子。这个食品商店通过类别、颜色以及种类来来组织它的食品。如图所示:
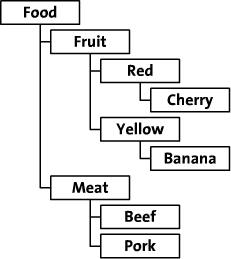
1)首先是邻接表模型。
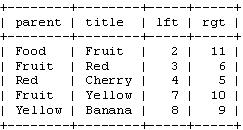
邻接表相当简单。只需要写一个递归函数来遍历这个树。我们的食品商店的例子用邻接表模型存储时看起来就像是这样:
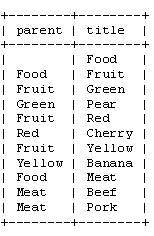
通过邻接表模型存储法中,我们可以看到Pear,它的父节点是Green,而Green的父节点又是Fruit,以此类推。而根节点是没有父节点的。这里为了方便观看,parent字段使用的字符串,实际应用中只要使用每个节点的ID即可。
现在已经在数据库中插入完毕数据,接下来开始先显示这棵树。
打印这棵树:
这里我们只需要写一个简单的递归函数就可以实现。打印某节点时,如果该节点有子节点就打印其子节点。源代码如下:
public static void displayTree(int parentId, int level)
throws SQLException {
setUp();
ResultSet result = dbc.query(
"SELECT ID, title FROM `adjacency_list` WHERE parentid="
+ parentId);
while(result.next()){
System.out.println(repeatStr(" ", level)
+ result.getString("title"));
displayTree(result.getInt("ID"), level+1);
}
}
要打印整棵树,我们只要运行代码:
displayTree(0, 0);
这个函数打印出以下结果:
Food
Fruit
Green
Pear
Red
Cherry
Yellow
Banana
Meat
Beef
Pork
求节点的路径
有时候我们需要知道某个节点所在的路径。举例来说,“Cherry”所在的路径为Food > Fruit > Red > Cherry。在这里,我们可以从Cherry开始查起,然后递归查询查询节点前的节点,直到某节点的父节点ID为0。源代码如下:
public static List<String> getPath(int id)
throws SQLException{
List<String> paths = new ArrayList<String>();
setUp();
ResultSet result = dbc.query(
"SELECT parentid, title FROM `adjacency_list` WHERE ID="
+ id);
result.next();
int parentid = result.getInt("parentid");
if(parentid != 0){
paths.addAll(getPath(parentid));
}
paths.add(result.getString("title"));
return paths;
}
我们用以下代码来打印结果:
List<String> paths = getPath(6);
int i = 0;
for(String path: paths){
System.out.println("[" + String.valueOf(i) + "] ==> " + path);
i++;
}
得到以下结果:
[0] ==> Food
[1] ==> Fruit
[2] ==> Red
[3] ==> Cherry
缺点
我们可以看到,用邻接表模型确实是个不错的方法。它简单易懂,而且实现的代码写起来也很容易。那么,缺点是什么呢?那就是,邻接表模型执行起来效率低下。我们对于每个结果,期望只需要一次查询;可是当使用邻接表模型时嵌套的递归使用了多次查询,当树很大的时候,这种慢就会表现得尤为明显。另外,对于一门程序语言来说,除了Lisp这种,大多数不是为了递归而设计。当一个节点深度为4时,它得同时生成4个函数实例,它们都需要花费时间、占用一定的内存空间。所以,邻接表模型效率的低下可想而知。
就像在程序世界经常遇到的一样。上帝是公平的,当在执行时效率低下,意味着可以增加预处理的程度。那么就让我们来看另外一种存储树形结构的方法。如之前所讲,我们希望能够减少查询的数量,最好是只做到查询一次数据库。
先来讲解一下原理。现在我们把树“横”着放。如下图所示,我们首先从根节点(“Food”)开始,先在它左侧标记“1”,然后我们到“Fruit”,左侧标记“2”,接着按照前序遍历的顺序遍历完树,依次在每个节点的左右侧标记数字。
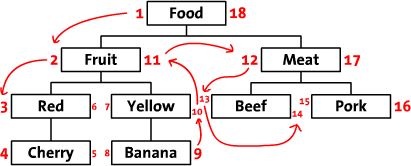
相信你也在图中发现一些规律,没错。比如,“Red”节点左边的数为3、右边的数为6,它是Food(1-18)的后代。同样的,我们可以注意到,左数大于2、右数小于11的节点都是“Fruit”的子孙。现在,所有的节点将以左数-右数的方式存储,这种通过遍历一个树、然后给每一个节点标注左数、右数的方式称为修改过的前序遍历算法。
2)修改过的前序遍历算法
在看完了介绍之后,我们要来讨论具体的实现。在这之前,先来看一下,数据库中表存储这些数的情况。
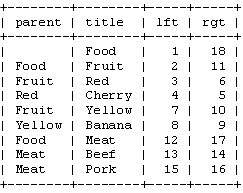
在这种存储方式中,我们实际上是不需要parent这个字段的。
打印树:
如之前的介绍。如果要想打印树,你只需要知道你要检索的节点。比如,想要打印“Fruit”的子树,可以查询左数大于2而小于11的节点。SQL语句就像这样:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
返回结果如下:
有时候,如果进行过增、删的操作,表中的数据可能就不是正确的顺序。没问题,只要使用“ORDER BY”语句就可以了,就像这样:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
现在唯一的问题是缩进问题。
正如我们面对树的问题常常会想到的方案——栈。这里,我们可以维护一个只保存右数的栈。当当前节点的右数值大于栈顶元素的值(说明栈顶元素的子树都以遍历完毕),这个时候弹出栈顶值。再循环检查栈顶值,直到栈顶值小于当前查询节点的右数值。这个时候只要检查栈中元素,有多少个元素说明当前查询节点有多少个祖先节点(设为n)。只需要打印n个空格即可。代码如下:
public static void displayTree(String root) throws SQLException{
setUp();
ResultSet result = dbc.query("SELECT lft, rgt "
+ "FROM `modified_preorder_travesal` WHERE title='"
+ root + "';");
result.next();
Stack<Integer> right = new Stack<Integer>();
result = dbc.query("SELECT title, lft, rgt "
+ "FROM `modified_preorder_travesal`"
+ " WHERE lft BETWEEN "
+ String.valueOf(result.getInt("lft"))
+ " AND "
+ String.valueOf(result.getInt("rgt"))
+ " ORDER BY lft ASC;");
while(result.next()){
if(right.size() > 0){
Integer current = right.peek();
while(current < result.getInt("rgt")){
right.pop();
current = right.peek();
}
}
System.out.println(repeatStr(" ", right.size())
+ result.getString("title"));
right.push(result.getInt("rgt"));
}
}
运行代码,打印结果和之前邻接表模型打印的结果一样。但是新方法更快,原因就是:没有递归,且一共只使用两次查询。
求节点的路径:
在修改过的前序遍历算法的实现中,我们同样需要求节点的路径。不过这不是很困难,对于某节点,我们只需求出左数值小于其左数值、右数大于其右数的所有节点。比如说“Cherry”这个节点(4-5),我们可以这么写SQL查询:
SELECT title FROM tree WHERE lft < 4 AND rgt > 5 ORDER BY lft ASC;
这里同样别忘了添加“ORDER BY”语句。执行以后返回结果:
求有多少子孙:
已知某节点的左数和右数,它的子孙的求法也就相当简单了,用如下方法:
descendants = (right - left - 1) / 2
自动生成表:
这儿的自动生成表指的是:如何把一个表从邻接表模型转换成修改过的前序遍历模型。我们在开始的临界表上增加"lft“和”rgt“字段。执行以下代码,完成转换:
public static int rebuildTree(int parentId, int left) throws SQLException {
setUp();
int right = left + 1;
ResultSet result = dbc.query("SELECT ID, title FROM `adjacency_list` WHERE "
+ "parentid=" + parentId);
while(result.next()){
right = rebuildTree(result.getInt("ID"), right);
}
dbc.update("UPDATE `adjacency_list` SET lft=" + String.valueOf(left)
+ ", rgt=" + String.valueOf(right)
+" WHERE ID='" + parentId + "';");
return right + 1;
}
开始执行只要运行以下代码:
rebuildTree(1, 1);
我们所写的运行函数是一个递归函数。对于某一节点,如果其没有子孙节点,那么他的右数值等于左数值+1;如果有那么返回其子树右数值+1。这个函数稍微有点复杂,不过梳理通了以后就不难理解。
这个函数将会从根节点开始遍历整个树。运行了可以发现和我们之前手动所建的表一样。这里有个快速检查的方法:那就是检查根节点的右数值,如果它等于节点总数的2倍,那就是正确的。
增加节点:
增加节点有两种方法:1)保留parentid字段,当增加节点后,运行一遍“rebuildTree”方法。这么做看起来很简单,不过你应该知道,这么做效率低下,尤其是大树时。那么第二种方法呢?2)首先我们得为添加的节点腾出空间。比如,我们想添加“Strawberry“到”Red“节点下,那么“Red”节点的右数就得从6到8,而“Yellow”就得从7-10变成9-12,以此类推。更新Red节点就意味着大于5的左数和右数都要增加2。
我们先运行以下SQL语句:
UPDATE tree SET rgt=rgt+2 WHERE rgt>5; UPDATE tree SET lft=lft+2 WHERE lft>5;
现在我们可以添加“Strawberry”到“Red”下,其左数为6、右数为7。
INSERT INTO tree SET lft=6, rgt=7, title='Strawberry';
再次运行“displayTree”方法,会发现“Strawberry”已被添加其中。删除节点有着差不多的步骤,这里就略去不提了。各位感兴趣的话可以自己实现。
缺点:
首先,修改过的前序遍历算法似乎更难理解。但是它有着邻接表模型无法比拟的速度优势,虽然,在增或着删数据的时候步骤多了些,但是,查询的时候只需要一条SQL语句。不过,这里我要提醒,当使用前序遍历算法存储树的时候,要注意临界区问题,就是在增或者删的时候,不要出现其他的数据库操作。
关于在数据库中存储层级数据的内容就讲到这里。如果你使用的Python语言的Django框架,应该觉得庆幸。因为已经有开源插件帮你实现了。项目名字叫MPTT,主页在这里。以后,我会对MPTT的用法以及源码实现作详细说明。在此之前,如果能力够,参考官方文档就可以了。
备注一:
各种数据库的JDBC驱动连接方式及下载,见这里。Mysql下载的快速链接。
下载完解压缩,把其中的mysql-connector-java-***-bin.jar(***为版本)文件拷贝至"yourjdkpath"/jre/lib/ext,我的路径为:/usr/lib/jvm/java-6-openjdk/jre/lib/ext/。
这个文件夹是只读的,修改权限用chmod命令。
连接数据库的参考代码:
import java.io.*;
import java.sql.*;
import java.util.*;
public class DBConnection {
private String driver = null;
private String url = null;
private String username = null;
private String password = null;
private Connection con = null;
public DBConnection(){
this.driver = "org.gjt.mm.mysql.Driver";
this.url = "jdbc:mysql://localhost:3306/Tree";
this.username = "root";
this.password = "";
}
public DBConnection(String driver, String url, String username, String password){
this.driver = driver;
this.url = url;
this.username = username;
this.password = password;
}
public Connection makeConnection(){
con = null;
try{
Class.forName(driver);
con = DriverManager.getConnection(url, username, password);
System.out.println("连接Mysql成功");
}
catch(SQLException sqle){
sqle.printStackTrace();
}
catch(ClassNotFoundException ex){
ex.printStackTrace();
}
return con;
}
public void closeConnection(){
try{
con.close();
}
catch(SQLException sqle){
sqle.printStackTrace();
}
}
public static void main(String[] args){
DBConnection dbc = new DBConnection();
dbc.makeConnection();
dbc.closeConnection();
}
}










树的增删改查会导致整个编码都更新吧.
这也是前序遍历算法的问题,增或者删需要改动非常多的数据,也就是在对数据的处理上需要花费较多的时间。因此,在查询上花费的时间就相对少了。
所以很难在项目中应用.
两种方法都在项目中使用过,由于都是小项目,所以对比效果不明显。比较折中的办法,是保存所有父节点id来组成TreeCode,当然,这样的话也只能应付小项目
给楼主点个赞
还有一种闭包表可以讲讲
给作者留言
关于作者
残阳似血(@秦续业),程序猿一枚,把梦想揣进口袋的挨踢工作者。现加入阿里云,研究僧毕业于上海交通大学软件学院ADC实验室。熟悉分布式数据分析(DataFrame并行化框架)、基于图模型的分布式数据库和并行计算、Dpark/Spark以及Python web开发(Django、tornado)等。
博客分类
搜索
点击排行
标签云
扫描访问
主题
残阳似血的微博
登录