Django中模拟微博timeline
相信大家都用过微博,我们在微博的timeline中,常常可以看到文字、音乐、视频等等的混合。所有的内容都聚合在一起显示出来。具体的实现未可知,但是在Django中,我们有比较优雅的方式。那就是使用contenttypes模块来实现。
现在我们假设对于一条微博只有三种方式(其他的很容易拓展):文本,音乐以及视频。我们先定义三个简单的Model。(注意到Music和Video只要简单继承Tweet类即可。)
from django.db import models
from django.contrib.auth.models import User
class Tweet(models.Model):
user = models.ForeignKey(User) # 这里就用Django自带的User
content = models.CharField(max_length=140) # 内容,最多140字
pic_url = models.URLField(null=True, blank=True)
created = models.DateTimeField(auto_now_add=True)
class Meta:
ordering = ['-created',]
def __unicode__(self):
return self.content
class Music(Tweet):
music_url = models.URLField(verify_exists=False)
class Video(Tweet):
video_url = models.URLField(verify_exists=False)
Django开发中使用Google custom search API
我们的网站通常都要集成搜索服务。通常情况下,我们都使用自己的搜索后端,例如使用Django,对于Python,我们主要有两种选择,一种是Whoosh,它是纯Python写成的搜索后端;另一种则是著名的Lucene的Python扩展,PyLucene,要提醒使用PyLucene,需要安装JVM。以后的文章我会介绍他们。
不过,今天的主角显然不是它们。因为有时候,我们并不需要这么麻烦,有时我们只需要集成一个Google搜索在其中就可以了。那么,Google custom search就派上了用场。在这里,我们也有三种方案:
- 用iframe版本的cse,使用这种方式,甚至不需要写什么代码。
- 使用Google ajax API,使用ajax方式获取搜索结果,然后用js将结果呈现在页面上。
- 使用Custom search API,在后端使用Python的http编程,远程获取json方式的结果,并把数据渲染到模板中。
在一切开始之前,必须先创建一个新的自定义搜索。在cse页面上,点击“Create a Custom Search Engine”,如果已经新建过了,点击下面的“manage your existing search engines”。
Python中time模块详解
在平常的代码中,我们常常需要与时间打交道。在Python中,与时间处理有关的模块就包括:time,datetime以及calendar。这篇文章,主要讲解time模块。
在开始之前,首先要说明这几点:
- 在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时间字符串 3)元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
- UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
- 时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。返回时间戳方式的函数主要有time(),clock()等。
- 元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
Django mptt介绍以及使用
Django mptt是个Django第三方组件,目标是使Django项目能在数据库中存储层级数据(树形数据)。它主要实现了修改过的前序遍历算法,如果你对原理还不是很了解,可以看我的这篇文章。当然,使用mptt时,原理是可以不用了解的,因为具体的实现细节都已经隐藏。不过,如果项目不是使用的Django,可以参考具体的实现原理。
在整篇文章中,我们将会拿《在数据库中存储层级结构》中的例子作为本文的例子。我们打算在数据库中存储这张图中的数据:
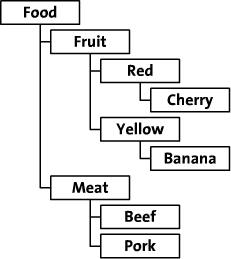
在介绍mptt之前,如果你的需求仅仅是像这样显示以上数据:
- Fruit
- Red
- Cherry
- Yellow
- Banana
- Red
- Meat
- Beef
- Pork
mptt就显得大材小用了,因为Django已经有内置模板过滤器来完成这个工作:unordered_list(官方文档)。如果你的需求不只这么简单,那就跳过这一段。不过这里还是要讲解一下unordered_list的做法。我们就来实现以上的结果。
Django开发中整合新浪微博API
Update:如果想了解更多第三方帐号登录,请看这篇文章。
随着新浪微博用户日益增加,我们有时候会考虑在自己的网站中整合新浪微博。比如说我现在的独立博客。
在我的博客中做到整合主要就这几方面:我写一篇文章,就会同步发送至微博。同时呢,用户可以用微博帐号登录,并且可以选择把对文章的评论,同步评论到文章的微博。另外,用户可以选择是否把博客留言同步至新浪微博。
首先要涉及的问题,就是用户用新浪微博帐号登录的问题,即授权机制。基本方法有两种:
- OAuth
- Basic auth(需要强调的是,微博开放平台将于6月1日正式停止Basic Auth的支持。因此,此种方法不作讨论了,其实需要用户名和密码的方式本身就不安全。)
OAuth新浪官方的文档在这里。想要了解OAuth技术说明的可以访问官方网站。
其实,OAuth的流程还是很简单的。大致如下:
- 向API调用获得request token。
- 将用户重定向到授权页(auth url)。
- 用户输入用户名和密码完成授权。重定向到Callback_url。
- 用request token向新浪微博换取access token。
- 完成。
