Dpark源码剖析
Spark是一个当下很火的集群计算平台,来自于加州大学伯克利分校的AMPLab,目前从Apache孵化器毕业,成为了Apache基金会下的顶级项目。现在的spark类似于hadoop,逐渐成长为一种生态系统。如下图所示,其上层包含了一系列计算工具,包括:
- Shark for SQL,查询hadoop数据的分布式SQL查询引擎,类似于hadoop上的hive,但效率更高。
- Streaming,利用spark来进行大规模流式数据处理。
- MLlib,基于spark的机器学习库。
- Graphx,spark之上的图计算框架,支持Pregel和GraphLab的计算模型。
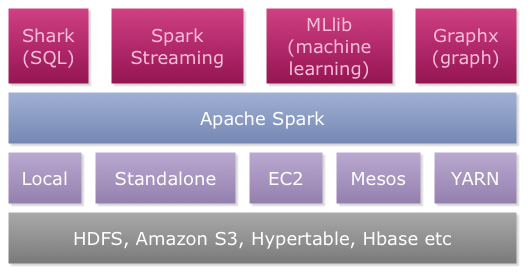
从spark创建之初,其对hadoop的支持就相当充分,当然一部分原因来自于Scala语言和Java语言交互的便利性。由上图可以看出,spark支持从HDFS等读出数据。尽管最开始,spark最先支持的是mesos(一个统一资源管理和调度平台),但在hadoop Yarn推出之后亦能很好地支持。除此之外,Spark能以本地多线程方式运行(local模式),也能以脱离mesos和Yarn的方式运行(standalone模式)。
Spark发展地如火如荼,尽管对于正常使用来说,我们不需要了解其内部的实现。但是要想深入优化上层应用,对底层的实现的了解是在所难免的。但是由于Scala语言的障碍,要想学习Spark需要从scala开始,学习曲线未免长了点。好在豆瓣的同学实现了一个spark的Python克隆:Dpark,其完全用Python语言翻译了spark。经过一段时间的研究,我对dpark的源码也有了一定程度的了解,因此就想写个系列来介绍其运行的原理。
然而Dpark有着不少的缺陷,下面就一一列举:
- 由于dpark翻译的时间较早(应该是spark 0.5前的版本,而spark目前最新版本已经是0.9),支持已经非常陈旧了。尽管dpark中RDD(spark中重要概念,表示弹性分布式数据集)还是内存层面上的抽象,而spark中的RDD是对内存和磁盘的统一抽象,另外缺少了上层的计算工具,但是其整体的思想是没有什么变化的。
- 对Hadoop的支持非常糟糕,dpark不支持从HDFS读取数据,取代支持的为分布式文件系统MooseFS;另外也不支持Yarn,当然还是支持mesos来进行调度的。
- 社区滞后,dpark目前的资料匮乏,开发也仅限于豆瓣的同学,没有来自社区的力量。spark则正好相反,社区的发展日益蓬勃,从底层到上层都有来自社区的大量贡献。
- GIL的限制,dpark中用多进程取代了spark中的多线程。
- 性能不佳,根据豆瓣的官方资料,dpark的性能甚至不如hadoop,这点让我比较吃惊。看来Python语言的性能劣势抵消了架构上带来的好处。
这些缺陷不能说dpark没有意义,其还是很好的学习工具。本来我研究dpark的初衷,是想完善其对Hadoop的支持,并移植spark graphx到dpark上。现在我更倾向于回归spark中,但是通过对dpark的研究,上手spark应该也更加容易。
Spark经过这么多版本的迭代,基本思想没有太大变化。我希望通过这个系列,能让大家能更容易地了解dpark/spark。本文也会作为系列的索引,并随着系列的进展而更新。










哪里有说dpark性能不如hadoop?我们也在用dpark
Davies的一个PPT里的,不过是两年前的了。地址:http://velocity.oreilly.com.cn/2011/ppts/dpark.pdf
嗯,应该比Java的MR慢,但Davies也说了:
"
DPark+MooseFS 应该可以做到被所有基于Hadoop的Python框架更快, 因为它底层的依赖最轻, 没有JVM的拖累启动任务也很快. DPark 在Shuffle时不排序, Reduce 时尽量多使用内存.
"
另外,spark的python api也越来越完善了,之后可以试试
赞~ 还有后续剖析么?
有的,之前太忙,后面有空就会补上后面的部分。
ajax test
感谢博主分享
这些公司很好地完成了工作并提供了很好的服务。我还需要时使用它们。
你知道布布扎勋爵就像地球上的上帝吗?当我的丈夫告诉我,我们之间已经结束并需要离婚时,这就像是一个梦想,理查德是我生命中的爱,我们彼此相爱,我们不能长时间彼此远离,我们一起做所有事情,我们的婚姻生活是美好而美丽的,直到我们听到一个误解和战斗然后理查德填补离婚并告诉我它已经结束,我尽力阻止他,但他拒绝。我很沮丧,哭着告诉我的朋友,当我的朋友告诉我布布扎勋爵如何重新统一婚姻时,理查德采取了这个决定,所以我立即通过WhatsApp联系了布布扎勋爵:+1 505 569 0396并告诉他我的情况,他回答说他说将帮助我完成他的咒语,我将在12至16小时内看到结果。我完成了他告诉我的事情,当我的丈夫打电话给我并说他很抱歉并取消了离婚时,我感到非常惊讶。布布扎勋爵是地球上的神通过电子邮件联系他:lordbubuzamiraclework@hotmail.com或通过WhatsApp:+1 505 569 0396
给作者留言
关于作者
残阳似血(@秦续业),程序猿一枚,把梦想揣进口袋的挨踢工作者。现加入阿里云,研究僧毕业于上海交通大学软件学院ADC实验室。熟悉分布式数据分析(DataFrame并行化框架)、基于图模型的分布式数据库和并行计算、Dpark/Spark以及Python web开发(Django、tornado)等。
博客分类
搜索
点击排行
标签云
扫描访问
主题
残阳似血的微博
登录