PyOdps 0.4版本发布,从一个故事说起
有这么个故事(如有雷同,纯属巧合)。有一天,某运营同学给某开发同学一个excel文件,里面是个客户清单。
“帮我查下这些用户的消耗呢”。
开发同学扫了一眼,几百个用户。这个事肯定是可以办的,但是想到麻烦程度,开发同学心里肯定是有不少羊驼经过的啦。
“有点麻烦啊”,开发同学轻轻抱怨。
“我懂的,把这个表和ODPS里的表join下就好了嘛。”运营同学努努嘴。
“……”。于是,开发同学把excel数据导出成文本格式,然后dship上传到ODPS,ODPS上编写SQL,dship下载,大功告成。
这里说得很轻松,但其实整个过程真的挺麻烦呢。要是这个过程中还要对excel中的数据进行过滤,最终结果还要绘个图,还是需要不少时间。
但是,如果这个开发同学使用PyOdps 0.4+版本新特性,一切就都轻松写意了。
为了模拟这个过程,我们拿movielens 100K的数据做例子,现在本地有一个excel表格,里面有100个需要查询的用户,表格包含两个字段,分别是用户ID和年龄。在ODPS上,我们有一张电影评分表,现在我们要求出这100用户个中年龄在20-30之间,按每个年龄来求电影评分均值,并用条形图展现。
可以想象,这个过程如果按照前面的描述,有多麻烦。那么用PyOdps DataFrame API呢。
首先,我们读出本地Excel文件。

In [14]: from odps.df import read_excel
In [15]: users = read_excel('/Users/chine/userids.xlsx')
In [16]: users.head(10)
|==========================================| 1 / 1 (100.00%) 0s
Out[16]:
id age
0 46 27
1 917 22
2 217 22
3 889 24
4 792 40
5 267 23
6 626 23
7 433 27
8 751 24
9 932 58
In [40]: users.count()
|==========================================| 1 / 1 (100.00%) 0s
100
然后我们用join语句,过滤出来电影评分表中这些用户的评分数据。
In [17]: ratings = DataFrame(o.get_table('pyodps_ml_100k_ratings'))
In [18]: ratings.head(10)
|==========================================| 1 / 1 (100.00%) 2s
Out[18]:
user_id movie_id rating unix_timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
5 298 474 4 884182806
6 115 265 2 881171488
7 253 465 5 891628467
8 305 451 3 886324817
9 6 86 3 883603013
In [25]: filter_ratings = ratings.join(users.filter(users.age.between(20, 30)), ('user_id', 'id'))[ratings, lambda x, y: y.age]
# 这里做字段抽取时,可以使用Collection,也可以使用lambda表达式,参数是左右两个Collection
In [26]: filter_ratings.head(10)
|==========================================| 1 / 1 (100.00%) 44s
Out[26]:
user_id movie_id rating unix_timestamp age
0 3 350 3 889237076 23
1 3 332 1 889237224 23
2 3 327 4 889237455 23
3 3 341 1 889237055 23
4 3 317 2 889237482 23
5 3 336 1 889237198 23
6 3 322 3 889237269 23
7 3 323 2 889237269 23
8 3 339 3 889237141 23
9 3 268 3 889236961 23
然后我们就可以按年龄聚合,求出评分均值啦。绘图也一气呵成。
In [28]: age_ratings = filter_ratings.groupby('age').agg(lambda x: x.rating.mean())
In [29]: age_ratings.head(10)
|==========================================| 1 / 1 (100.00%) 30s
Out[29]:
age rating_mean
0 20 4.002309
1 21 4.051643
2 22 3.227513
3 23 3.519174
4 24 3.481013
5 25 3.774744
6 26 3.391509
7 27 3.355130
8 28 3.382883
9 29 3.705660
In [30]: age_ratings.plot(kind='bar', x='age', rot=45)
|==========================================| 1 / 1 (100.00%) 29s
Out[30]: <matplotlib.axes._subplots.AxesSubplot at 0x10b875f10>

超级简单,有木有!
这里的users其实是存在于本地的,而ratings是存在于ODPS上,用户依然可以join这两个Collection。其实对于0.4之前的版本,本地数据上传的接口也很容易(但是无法使用DataFrame API来进行本地过滤),但是对于0.4版本,不管一个Collection是存在于ODPS还是本地,用户都可以执行join和union的操作。
而这一切都源自0.4版本带来的新特性,DataFrame API的pandas计算后端。
DataFrame API使用pandas计算
我们知道,PyOdps DataFrame API类似于pandas的接口,但还是有些许不同的,那我们为什么不能用pandas来执行本地计算呢,这样也能充分利用pandas的一些特性,如支持各种数据输入。
所以,除了过去使用odps.models.Table来初始化DataFrame,我们也可以使用pandas DataFrame来初始化。
In [41]: import numpy as np
In [42]: import pandas as pd
In [44]: pandas_df = pd.DataFrame(np.random.random((10, 3)), columns=list('abc'))
In [45]: pandas_df
Out[45]:
a b c
0 0.583845 0.301504 0.764223
1 0.153269 0.335511 0.455193
2 0.725460 0.460367 0.294741
3 0.315234 0.907264 0.849361
4 0.678395 0.642199 0.746051
5 0.977872 0.841084 0.931561
6 0.903927 0.846036 0.982424
7 0.347098 0.373247 0.193810
8 0.672611 0.242942 0.381713
9 0.461411 0.687164 0.514689
In [46]: df = DataFrame(pandas_df)
In [49]: type(df)
Out[49]: odps.df.core.DataFrame
In [47]: df.head(3)
|==========================================| 1 / 1 (100.00%) 0s
Out[47]:
a b c
0 0.583845 0.301504 0.764223
1 0.153269 0.335511 0.455193
2 0.725460 0.460367 0.294741
In [48]: df[df.a < 0.5].a.sum()
|==========================================| 1 / 1 (100.00%) 0s
1.2770121422535428
这里转化成PyOdps DataFrame后,所有的计算也一样,变成延迟执行,PyOdps DataFrame在计算前的优化也同样适用。
这样做的好处是,除了前面我们提到的,能结合本地和ODPS做计算外;还有个好处就是方便进行本地调试。所以,我们可以写出以下代码:
DEBUG = True
if DEBUG:
# 这个操作使用tunnel下载,因此速度很快。对于分区表,需要给出所有分区值。
df = ratings[:100].to_pandas(wrap=True)
else:
df = ratings
在DEBUG的时候,我们能够利用PyOdps DataFrame在对原始表做切片操作时使用tunnel下载,速度很快的特性,选择原始表的一小部分数据来作为本地测试数据。值得注意的是, 本地计算通过不一定能在ODPS上也计算通过,比如自定义函数的沙箱限制 。
目前pandas计算后端尚不支持窗口函数。
apply和MapReduce API
使用apply对单行数据调用自定义函数
以前我们对于某个字段,能调用map来使用自定义函数,现在结合axis=1的apply,我们能对一行数据进行操作。
In [13]: ratings.apply(lambda row: row.rating / float(row.age), axis=1, reduce=True, types='float', names='rda').head(10)
|==========================================| 1 / 1 (100.00%) 1m44s
Out[13]:
rda
0 0.166667
1 0.166667
2 0.208333
3 0.208333
4 0.125000
5 0.208333
6 0.166667
7 0.208333
8 0.208333
9 0.125000
reduce为True的时候,会返回一个sequence,详细参考文档。
MapReduce API
PyOdps DataFrame API也提供MapReduce API。我们还是以movielens 100K为例子,看如何使用。
现在假设我们需要求出每部电影前两名的评分,直接上代码。
from odps.df import output
@output(['movie_id', 'movie_title', 'movie_rating'], ['int', 'string', 'int'])
def mapper(row):
yield row.movie_id, row.title, row.rating
@output(['title', 'top_rating'], ['string', 'int'])
def reducer(keys):
i = [0]
def h(row, done):
if i[0] < 2:
yield row.movie_title, row.movie_rating
i[0] += 1
return h
In [7]: top_ratings = ratings.map_reduce(mapper, reducer, group='movie_id', sort='movie_rating', ascending=False)
In [10]: top_ratings.head(10)
|==========================================| 1 / 1 (100.00%) 3m48s
Out[10]:
title top_rating
0 Toy Story (1995) 5
1 Toy Story (1995) 5
2 GoldenEye (1995) 5
3 GoldenEye (1995) 5
4 Four Rooms (1995) 5
5 Four Rooms (1995) 5
6 Get Shorty (1995) 5
7 Get Shorty (1995) 5
8 Copycat (1995) 5
9 Copycat (1995) 5
利用刚刚说的本地DEBUG特性,我们也能使用本地计算来验证,计算结果能很快得出。人生苦短!
In [22]: local_ratings = ratings[:100].to_pandas(wrap=True)
|==========================================| 1 / 1 (100.00%) 2s
In [23]: local_ratings.map_reduce(mapper, reducer, group='movie_id', sort='movie_rating', ascending=False).head(10)
|==========================================| 1 / 1 (100.00%) 0s
Out[23]:
title top_rating
0 Shanghai Triad (Yao a yao yao dao waipo qiao) ... 5
1 Twelve Monkeys (1995) 4
2 Seven (Se7en) (1995) 4
3 Usual Suspects, The (1995) 5
4 Postino, Il (1994) 3
5 Mr. Holland's Opus (1995) 4
6 Taxi Driver (1976) 5
7 Crumb (1994) 5
8 Star Wars (1977) 5
9 Star Wars (1977) 5
cache机制
在0.4之前的版本,我们提供了一个persist接口,来保存执行结果。但是这个操作是个立即执行接口。现在我们提供cache接口,cache的collection会被单独计算,但不会立即执行。
In [25]: tmpdf = ratings[ratings.title.len() > 10].cache()
In [26]: tmpdf['title', 'movie_id'].head(3)
|==========================================| 1 / 1 (100.00%) 35s
Out[26]:
title movie_id
0 Seven (Se7en) (1995) 11
1 Event Horizon (1997) 260
2 Star Wars (1977) 50
In [27]: tmpdf.count() # tmpdf已经被cache,所以我们能立刻计算出数量
|==========================================| 1 / 1 (100.00%) 0s
99823
记住,目前的cache接口,计算的结果还是要落地的,并不是存放在内存中。
而一个collection如果已经被计算过,这个过程会自动触发cache机制,后续的计算过程会从这计算个向后进行,而不再需要从头计算。
其他特性
PyOdps 0.4版本还带来一些其他特性,比如join支持mapjoin(只对ODPS后端有效);Sequence上支持unique和nunique;execute_sql执行时支持设置hints,对于IPython插件,支持使用SET来设置hints,等等。
PyOdps下一步计划
对于PyOdps的DataFrame API来说,我们的短期目标是能完成ODPS SQL能做的所有事情,然后在这个基础上再带来更多SQL不容易做到的,但是却很有用的操作。现在,除了自定义聚合函数,我们已经能基本涵盖所有的SQL场景。
PyOdps非常年轻,期待大家来使用、提feature、贡献代码。
- 安装方法:pip install pyodps
- Github:https://github.com/aliyun/aliyun-odps-python-sdk
- 文档:http://pyodps.readthedocs.org/
- bug report:https://github.com/aliyun/aliyun-odps-python-sdk/issues
PyOdps在交互式环境下的使用,让探索ODPS数据更容易些
春节结束了,是时候来些新鲜玩意,让我们来看一些酷的东西。
当当当当:隆重推出PyOdps logo。
好像跑题了,好吧,让我们言归正传。
我们知道Python提供了一个交互式的环境,能够方便探索和试验想法。同时,IPython是Python交互环境的增强,提供了很多强大的功能;IPython Notebook(现在已经是Jupyter Notebook)则更酷,提供了一个web界面,除了提供交互环境,还是一个记录计算过程的『笔记本』。
PyOdps也提供了一系列在交互式环境下的增强工具,使得探索ODPS数据更方便快捷。
配置ODPS帐号
Python交互环境
同一个环境支持配置若干个ODPS帐号,只需要:
In [1]: from odps.inter import setup
In [2]: setup('**your-access_id**', '**your-access-key**', '**your-project**', endpoint='**your-endpoint**')
此时这个帐号会被配置到一个叫做default的我们称之为room的地方。以后我们再使用这个帐号只需要:
In [3]: from odps.inter import enter
In [4]: room = enter()
In [5]: o = room.odps
In [6]: o.get_table('dual')
Out[6]:
odps.Table
name: odps_test_sqltask_finance.`dual`
schema:
c_int_a : bigint
c_int_b : bigint
c_double_a : double
c_double_b : double
c_string_a : string
c_string_b : string
c_bool_a : boolean
c_bool_b : boolean
c_datetime_a : datetime
c_datetime_b : datetime
通过room的odps属性,我们可以取到ODPS的入口,这样就可以接着进行ODPS操作了。配置了别的room比如叫做myodps,要取到ODPS入口,只需要enter('myodps').odps即可。
list_rooms方法能列出所有的room。
In [17]: from odps.inter import list_rooms In [18]: list_rooms() Out[18]: ['default', 'meta']
IPython及Jupyter Notebook
PyOdps还提供了IPython插件。首先我们需要加载插件:
In [11]: %load_ext odps
In [14]: %enter
Out[14]:
In [15]: o = _.odps
In [16]: o.get_table('dual')
Out[16]:
odps.Table
name: odps_test_sqltask_finance.`dual`
schema:
c_int_a : bigint
c_int_b : bigint
c_double_a : double
c_double_b : double
c_string_a : string
c_string_b : string
c_bool_a : boolean
c_bool_b : boolean
c_datetime_a : datetime
c_datetime_b : datetime
_下划线能取到上一步的结果。
保存常用的ODPS对象
room除了提供ODPS入口的功能,还能保存常用的ODPS对象。比如,我们能把常用的表起个名字,给保存起来。
In [19]: iris = o.get_table('pyodps_iris')
In [23]: room.store('iris_test', iris, desc='保存测试ODPS对象')
In [28]: room['iris_test']
Out[28]:
odps.Table
name: odps_test_sqltask_finance.`pyodps_iris`
schema:
sepallength : double
sepalwidth : double
petallength : double
petalwidth : double
name : string
In [29]: room.iris_test
Out[29]:
odps.Table
name: odps_test_sqltask_finance.`pyodps_iris`
schema:
sepallength : double
sepalwidth : double
petallength : double
petalwidth : double
name : string
这两种方式都可以取到保存的ODPS对象。如果要列出当前room保存的所有ODPS对象,则可以:
In [30]: room.display() Out[30]: default desc name iris_test 保存测试ODPS对象 iris 安德森鸢尾花卉数据集
也可以使用IPython插件命令:
In [31]: %stores Out[31]: default desc name iris_test 保存测试ODPS对象 iris 安德森鸢尾花卉数据集
要删除某个ODPS对象:
In [32]: room.drop('iris_test')
In [33]: %stores
Out[33]:
default desc
name
iris 安德森鸢尾花卉数据集
执行SQL命令
PyOdps提供了执行SQL的方法,但是在交互式环境下却不甚方便。使用PyOdps提供的IPython插件,可以通过sql命令来直接执行。
在执行时,需要配置全局帐号,如果已经使用了enter方法或者命令,则已经配置;如果没有,则会尝试enter默认的room;如果这也没有配置,则需要使用to_global方法。
In [34]: o = ODPS('**your-access-id**', '**your-secret-access-key**', project='**your-project**', endpoint='**your-end-point**'))
In [35]: o.to_global()
这时我们就可以使用sql命令,单个百分号输入单行SQL,多行SQL使用两个百分号:
In [37]: %sql select * from pyodps_iris limit 5 |==========================================| 1 / 1 (100.00%) 3s Out[37]: sepallength sepalwidth petallength petalwidth name 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa In [38]: %%sql ....: select * from pyodps_iris ....: where sepallength < 5 ....: limit 5 ....: |==========================================| 1 / 1 (100.00%) 15s Out[38]: sepallength sepalwidth petallength petalwidth name 0 4.9 3.0 1.4 0.2 Iris-setosa 1 4.7 3.2 1.3 0.2 Iris-setosa 2 4.6 3.1 1.5 0.2 Iris-setosa 3 4.6 3.4 1.4 0.3 Iris-setosa 4 4.4 2.9 1.4 0.2 Iris-setosa
在Jupyter Notebook里,多行SQL会提供语法高亮:

持久化pandas DataFrame为ODPS表
使用persist命令即可:
In [42]: import pandas as pd
In [43]: df = pd.read_csv('https://raw.github.com/pydata/pandas/master/pandas/tests/data/iris.csv')
In [48]: %persist df pyodps_iris_test
|==========================================| 150 /150 (100.00%) 0s
In [49]: from odps.df import DataFrame
In [61]: DataFrame(o.get_table('pyodps_iris_test')).head(5)
|==========================================| 1 / 1 (100.00%) 0s
Out[61]:
sepallength sepalwidth petallength petalwidth name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
其它交互式方面的增强
在交互式环境下,我们repr一个ODPS表的时候,会打印这个表的schema,包括字段注释,省去了查这个表的meta信息。
In [41]: o.get_table('china_stock', project='odpsdemo')
Out[41]:
odps.Table
name: odpsdemo.`china_stock`
schema:
d : string # 日期
c : string # 股票代码
n : string # 股票名称
t_close : double # 收盘价
high : double # 最高价
low : double # 最低价
opening : double # 开盘价
l_close : double # 昨日收盘价
chg : double # 涨跌额
chg_pct : double # 涨跌幅
vol : bigint # 成交量
turnover : double # 成交额
partitions:
code : string # 股票代码
当使用sql命令或者使用DataFrame框架计算的时候,在终端或者Jupyter Notebook里都提供一个进度条来方便用户来查看执行进度。

后记
PyOdps现在处于快速迭代阶段,我们所有的开发都是开源的。大家如果需要什么功能,可以给我们提issue(GitHub);也可以直接参与到开发,直接给我们发Pull Request就行啦。
欢迎大家一起来建设PyOdps。
github:https://github.com/aliyun/aliyun-odps-python-sdk
文档:http://pyodps.readthedocs.org/zh_CN/latest/
PyOdps DataFrame来临,大数据分析从未如此简单!
PyOdps正式发布DataFrame框架(此处应掌声经久不息),有了它,就像卷福有了花生,比翼双飞,哦不,如虎添翼。
快过年了,大家一定没心情看长篇大论的分析文章。作为介绍PyOdps DataFrame的开篇文章,我只说说其用起来爽的地方。其余的部分,从使用、问题到实现原理,我会分文章细说。
如果你不知道什么是ODPS,ODPS是阿里云旗下的大数据计算服务。如果不知道是DataFrame什么,它是存在于pandas和R里的数据结构,你可以把它当做是表结构。如果想快速浏览PyOdps DataFrame能做什么,可以看我们的快速开始文档。
让我们开始吧。
强类型支持
DataFrame API在计算的过程中,从字段到类型都是确定的,因此,若取一个不存在的字段,会丢给你个大大的异常。
In [4]: from odps.df import DataFrame
In [5]: iris = DataFrame(o.get_table('pyodps_iris'))
In [6]: iris.dtypes
Out[6]:
odps.Schema {
sepallength float64
sepalwidth float64
petallength float64
petalwidth float64
name string
}
In [7]: iris.field_not_exist
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in ()
----> 1 iris.field_not_exist
/Users/chine/Workspace/pyodps/odps/df/expr/expressions.pyc in __getattr__(self, attr)
510 return self[attr]
511
--> 512 raise e
513
514 def output_type(self):
AttributeError: 'DataFrame' object has no attribute 'field_not_exist'
如果取存在的字段,自然是没问题啦。
In [11]: iris.sepalwidth.head(5) |==========================================| 1 / 1 (100.00%) 0s Out[11]: sepalwidth 0 3.5 1 3.0 2 3.2 3 3.1 4 3.6
有些方法,比如说取平均数,非数字肯定是不能调用的咯。
In [12]: iris['name'].mean()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in ()
----> 1 iris['name'].mean()
/Users/chine/Workspace/pyodps/odps/df/expr/expressions.pyc in __getattribute__(self, attr)
171 if new_attr in self._get_attr('_args'):
172 return self._get_arg(new_attr)
--> 173 raise e
174
175 def _defunc(self, field):
AttributeError: 'Column' object has no attribute 'mean'
数字类型的字段则可以调用。
In [10]: iris.sepalwidth.mean() |==========================================| 1 / 1 (100.00%) 27s 3.0540000000000007
操作数据如此简单
我们常常需要select一个表字段,但是只是不需要一个字段,却需要写一堆SQL。在DataFrame API里,调用exclude方法就行了。
In [13]: iris.exclude('name').head(5)
|==========================================| 1 / 1 (100.00%) 0s
Out[13]:
sepallength sepalwidth petallength petalwidth
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
使用DataFrame写出来的代码,天然有Python的特点,清晰易懂。某些快捷API,能使得操作更加简单。
比如我们要取name的个数从大到小前10的值分别是多少。
In [16]: iris.groupby('name').agg(count=iris.name.count()).sort('count', ascending=False)[:10]
|==========================================| 1 / 1 (100.00%) 37s
Out[16]:
name count
0 Iris-virginica 50
1 Iris-versicolor 50
2 Iris-setosa 50
直接使用value_counts来得更快。
In [17]: iris['name'].value_counts()[:10]
|==========================================| 1 / 1 (100.00%) 34s
Out[17]:
name count
0 Iris-virginica 50
1 Iris-versicolor 50
2 Iris-setosa 50
很多时候,写一个SQL,我们需要检查中间结果的执行,就显得很麻烦,我们常常需要选取中间的SQL来执行,在DataFrame的世界,中间结果赋值一个变量就行了,这都不是事儿。
计算的过程和结果展示
在DataFrame的执行过程中,我们在终端里和IPython notebook里,都会有进度条显示任务的完成情况。结果的输出也会有更好的格式化展现,在IPython notebook里会以HTML表格的形式展现。

绘图集成
DataFrame的计算结果能直接调用plot方法来制作图表,不过绘图需要安装pandas和matplotlib。
In [21]: iris.plot() |==========================================| 1 / 1 (100.00%) 0s Out[21]: <matplotlib.axes._subplots.AxesSubplot at 0x10feab610>

导出数据再用excel画图,这事儿……咳咳,未来我们还会提供更好的可视化展现,比如提供交互式的图表。
自定义函数和Lambda表达式
DataFrame支持map方法,想对一个字段调用自定义函数非常方便。
In [30]: GLOBAL_VAR = 3.2
In [31]: def myfunc(x):
if x < GLOBAL_VAR:
return 0
else:
return 1
In [32]: iris['sepalwidth', iris.sepalwidth.map(myfunc).rename('sepalwidth2')].head(5)
|==========================================| 1 / 1 (100.00%) 18s
Out[32]:
sepalwidth sepalwidth2
0 3.5 1
1 3.0 0
2 3.2 1
3 3.1 0
4 3.6 1
可惜apply和聚合的自定义函数,暂时还不支持,期待吧!
延迟执行
DataFrame API的所有操作并不会立即执行,除非用户显式调用execute方法或者一些立即执行的方法。在交互式界面下,打印或者repr对象的时候,内部也会调用execute方法,方便用户使用。
执行优化
DataFrame框架在执行前会对整个查询进行优化,比如连续的projection合并。当用户查看原始表(或者选取某个分区)时,会使用tunnel来获取结果。
PyOdps DataFrame的下一步发展
好了,说了这么多,聊一聊我们DataFrame接下来要做的事情,首先,我们会实现多计算后端,包括pandas,当数据量比较小的时候,我们可以使用本地计算,而不需要等待ODPS的调度;其次,DataFrame框架和我们的机器学习部分会有更多的集成,从数据分析,到算法,一气呵成。
PyOdps非常年轻,才短短几个月的时间。我们的整个项目,在GitHub上开源。我个人非常希望大家能参与到开源的建设中来,能提个建议也是极好的。所以,我会写文章详述我们PyOdps的实现原理,希望大家一起把ODPS建设得更好。
github:https://github.com/aliyun/aliyun-odps-python-sdk
文档:http://pyodps.readthedocs.org/zh_CN/latest/
Dpark源码剖析一(概述)
Dpark/Spark中最重要的核心就是RDD(弹性分布式数据集,Resilient Distributed Datasets),为了给今后的分析打下基础,这篇文章首先会解释RDD相关的重要概念。接着会简单介绍dpark中的另外两个重要核心Accumulator(累加器)和Broadcast(广播变量),关于这两者这里只做简单介绍,我们后面会对分别单独对源码做分析。
Spark不光是用函数式语言scala写的,它也到处体现着函数式语言的特性。Dpark当然也继承了这些特性,这个我们接下来会逐一分析。类似于spark,dpark也是master-slave架构的,但不同于spark,dpark中仅提供了三种运行方式:本地模式(local,单进程)、多进程模式(实际上也是单机)以及mesos模式(使用mesos来调度达到分布式计算的目的)。
RDD
首先需要说明的是弹性分布式数据集(RDD),dpark和最新的spark这部分已经有所不同,主要体现在对内存和磁盘抽象上,下面包括以后的文章都会以dpark为准。
RDD听起来很玄乎,其实很简单。它是一个抽象,本质上表示大量的可迭代数据,这些数据可以直接存在于内存中,也可以延迟读取。但是数据量太大,怎么办?尝试把数据分成各个分片(split),每个分片对应着一部分数据,这样可以将一个RDD分开来存取和执行运算。RDD是不可变的,这符合函数式编程中的不可变数据的特性,不要小看这个特性,它其实在分布式计算的环境中非常重要,能简化分布式环境下的计算。
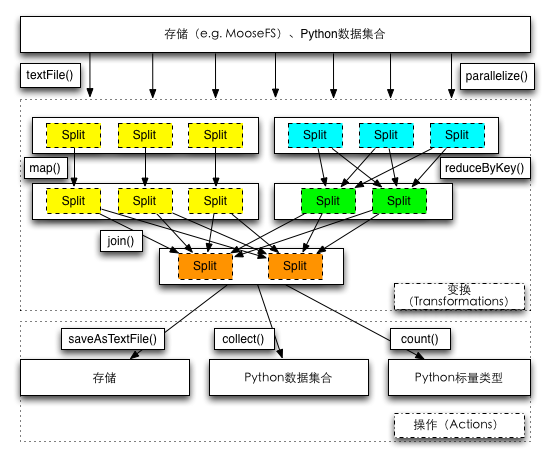
在dpark中,一个RDD中的元素通常来说有两种:一种是单一的值,还有一种是key和value组成的对(元组表达,(key, value))。如上图所示,RDD的数据来源也通常有两种:一种是Python数据集合(如list等),也可以是分布式文件系统(本地文件系统亦可,这种情况可以用在本地模式和多进程模式)。
我们来看看RDD的初始化以及重要的函数。
class Split(object):
def __init__(self, idx):
self.index = idx
class RDD(object):
def __init__(self, ctx):
self.ctx = ctx
self.id = RDD.newId()
self._splits = []
self.dependencies = []
self.aggregator = None
self._partitioner = None
self.shouldCache = False
self.snapshot_path = None
ctx.init()
self.err = ctx.options.err
self.mem = ctx.options.mem
@cached
def __getstate__(self):
d = dict(self.__dict__)
d.pop('dependencies', None)
d.pop('_splits', None)
d.pop('ctx', None)
return d
def _preferredLocations(self, split):
return []
def preferredLocations(self, split):
if self.shouldCache:
locs = env.cacheTracker.getCachedLocs(self.id, split.index)
if locs:
return locs
return self._preferredLocations(split)
def cache(self):
self.shouldCache = True
self._pickle_cache = None # clear pickle cache
return self
def snapshot(self, path=None):
if path is None:
path = self.ctx.options.snapshot_dir
if path:
ident = '%d_%x' % (self.id, hash(str(self)))
path = os.path.join(path, ident)
if not os.path.exists(path):
try: os.makedirs(path)
except OSError: pass
self.snapshot_path = path
return self
def compute(self, split):
raise NotImplementedError
def iterator(self, split):
if self.snapshot_path:
p = os.path.join(self.snapshot_path, str(split.index))
if os.path.exists(p):
v = cPickle.loads(open(p).read())
else:
v = list(self.compute(split))
with open(p, 'w') as f:
f.write(cPickle.dumps(v))
return v
if self.shouldCache:
return env.cacheTracker.getOrCompute(self, split)
else:
return self.compute(split)
这里Split类非常简单,只有个索引号index,表示是第几个分片。RDD的属性中的_splits指的是该RDD的所有分片。Split及其子类的作用是,告诉RDD该分片该如何计算,是读取分布式文件系统中的数据呢,还是读取内存中的列表的某一部分?Split中可以存放数据,也可以只提供读取数据需要的参数。
函数式编程中函数是一等公民,RDD也拥有大量的函数来进行计算。这些计算可以分为两类:变换(Transformations)和操作(Actions)。变换比如说map函数,它的参数是一个函数func,我们对于RDD中的每个元素,调用func函数将其变为另一个元素,这样就组成了新的RDD。类似的这种计算过程不是立即执行的,可能经历过多个变换后,等到需要将结果返回主程序时才执行,这个时候,从一个RDD到另一个RDD就是一个变换的过程。对于操作来说,执行的时候,相关的计算会立刻执行,并将结果返回(比如说reduce、collect等等)。计算的结果可以直接写入存储(比如调用saveAsTextFile),可以转化为Python集合数据(比如collect方法,返回包含全部数据的列表),也可以返回标量的结果(比如count方法,返回所有元素的个数)。
恰好是由于RDD的不可变性,在变换的过程中,我们只需记录下足够的信息,这时就可以在真正需要数据时执行计算。这种惰性计算的特点使得dpark/spark的计算相当高效。
那么这些信息包括什么呢?RDD的dependencies就是之一,它记录下了当前的RDD是从哪个或者哪些RDD得到的,这些依赖是Dependency类或者子类的实例,这在dpark中被称为血统(lineage),听起来很高大上吧?通过这些依赖,你就能得到一个RDD的父母或者祖先有哪些。关于具体的依赖关系,我们会在接下来文章中结合RDD的各种变换来详细说明。
这里需要先提下依赖的大致分类。dpark中,dependency可以分为两大类,窄依赖和宽依赖。什么叫窄依赖?非宽依赖是也,你会说,这不废话么?那就让我们先看看什么叫宽依赖。对于当前的RDD的一个分片,它的数据可能来自依赖RDD的任意分片,这就叫宽依赖。比如说对于存放键值对的依赖RDD,我们执行groupByKey操作,也就是把key相同的值都聚合起来,这时候,key可能存在于依赖RDD的任意分片,这就叫宽依赖。因此,窄依赖就显而易见了,对于当前RDD的一个分片,它只可能源自于依赖RDD的有限个分片,这就是窄依赖,比如说map操作,当前RDD的某分片中的每个元素就是由依赖RDD的对应的分片数据算来的。之所以这里先提下宽依赖和窄依赖,对后面的理解大有裨益。
RDD类中包含了一个compute接口,它的参数是一个分片。对于不同的RDD的子类,这个方法提供了给定分片的数据的生成方法。但是在这个接口外还包装了一个iterator方法,这才是内部运算时真正调用的方法,为什么呢?这里涉及到了snapshot和cache。下面逐一说明。
首先是snapshot。RDD中通过snapshot方法,将参数snapshot_path设置为创建的路径。而在iterator调用时,会根据snapshot_path是否为空来判断是否做snapshot。snapshot时,需要提供所有运算机器能够访问的共享的文件路径(包括分布式文件系统),这样,在iterator时首先判断是否需要做snapshot,如果要则判断对应的数据文件是否在,如果不在,则先创建,再将compute计算后的结果序列化后直接写入文件;如果存在,则直接读出并反序列化。
cache和snapshot的区别在于,cache是写入内存(在本地模式下);或者本地文件系统(其他模式),并让master记录下在那个机器做的cache以及路径(这么说不准确,但是可以这么理解)。这样就不需要一个共享的文件路径,同样在iterator调用的时候可以先从cache中读出(这里可能涉及到远程读取,因为写入的地方可能不在本地)。这里的过程会复杂得多,我们会在以后专门讲解,同学们只要留下印象即可。
另外一对重要的方法是_preferredLocations和preferredLocations(就一个下划线的区别),它们都表示该RDD的某个分片计算时期望执行的地址(在哪个机器上执行)。首先我们说说公有方法preferredLocations,首先如果一个RDD的分片做过cache,那么当然希望在有缓存的机器上执行,否则就返回私有方法_preferredLocations的结果。对于这个私有方法来说,具体的RDD子类会覆盖这个方法。比如说,一个RDD从分布式文件系统读取数据,我们知道,分布式文件中的文件以块的形式放在不同的机器上,那么我们当然希望这个RDD期望运行的地址是在读取块所在的机器上,这样能减少网络的开销;又比如,有着某个RDD的某个分片依赖于另一个RDD的一个分片,前者更倾向于在后者机器上执行计算,否则还需要进行一次拷贝操作。
值得一提的是RDD类的__getstate__方法,这个方法告诉序列化模块应该要序列化哪些属性。ctx表示表示程序运行入口的上下文,序列化不需要ok。但是为什么不序列化依赖和分片呢?这个留到后面解答。
Accumulator和Broadcast(共享变量)
除了RDD,dpark还提供了两种集群各机器间可以共享的变量。一个是累加器(Accumulator),一种在运行时只可以进行累加操作的变量;还有一个是广播变量(Broadcast),它用来将一个通常是较大的变量发布到所有的计算节点,这样避免了序列化和反序列化的开销。这里一笔带过,以后详述。
Dpark源码剖析
Spark是一个当下很火的集群计算平台,来自于加州大学伯克利分校的AMPLab,目前从Apache孵化器毕业,成为了Apache基金会下的顶级项目。现在的spark类似于hadoop,逐渐成长为一种生态系统。如下图所示,其上层包含了一系列计算工具,包括:
- Shark for SQL,查询hadoop数据的分布式SQL查询引擎,类似于hadoop上的hive,但效率更高。
- Streaming,利用spark来进行大规模流式数据处理。
- MLlib,基于spark的机器学习库。
- Graphx,spark之上的图计算框架,支持Pregel和GraphLab的计算模型。
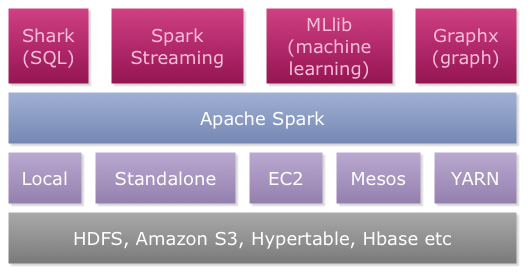
从spark创建之初,其对hadoop的支持就相当充分,当然一部分原因来自于Scala语言和Java语言交互的便利性。由上图可以看出,spark支持从HDFS等读出数据。尽管最开始,spark最先支持的是mesos(一个统一资源管理和调度平台),但在hadoop Yarn推出之后亦能很好地支持。除此之外,Spark能以本地多线程方式运行(local模式),也能以脱离mesos和Yarn的方式运行(standalone模式)。
Spark发展地如火如荼,尽管对于正常使用来说,我们不需要了解其内部的实现。但是要想深入优化上层应用,对底层的实现的了解是在所难免的。但是由于Scala语言的障碍,要想学习Spark需要从scala开始,学习曲线未免长了点。好在豆瓣的同学实现了一个spark的Python克隆:Dpark,其完全用Python语言翻译了spark。经过一段时间的研究,我对dpark的源码也有了一定程度的了解,因此就想写个系列来介绍其运行的原理。
然而Dpark有着不少的缺陷,下面就一一列举:
- 由于dpark翻译的时间较早(应该是spark 0.5前的版本,而spark目前最新版本已经是0.9),支持已经非常陈旧了。尽管dpark中RDD(spark中重要概念,表示弹性分布式数据集)还是内存层面上的抽象,而spark中的RDD是对内存和磁盘的统一抽象,另外缺少了上层的计算工具,但是其整体的思想是没有什么变化的。
- 对Hadoop的支持非常糟糕,dpark不支持从HDFS读取数据,取代支持的为分布式文件系统MooseFS;另外也不支持Yarn,当然还是支持mesos来进行调度的。
- 社区滞后,dpark目前的资料匮乏,开发也仅限于豆瓣的同学,没有来自社区的力量。spark则正好相反,社区的发展日益蓬勃,从底层到上层都有来自社区的大量贡献。
- GIL的限制,dpark中用多进程取代了spark中的多线程。
- 性能不佳,根据豆瓣的官方资料,dpark的性能甚至不如hadoop,这点让我比较吃惊。看来Python语言的性能劣势抵消了架构上带来的好处。
这些缺陷不能说dpark没有意义,其还是很好的学习工具。本来我研究dpark的初衷,是想完善其对Hadoop的支持,并移植spark graphx到dpark上。现在我更倾向于回归spark中,但是通过对dpark的研究,上手spark应该也更加容易。
Spark经过这么多版本的迭代,基本思想没有太大变化。我希望通过这个系列,能让大家能更容易地了解dpark/spark。本文也会作为系列的索引,并随着系列的进展而更新。
