Dpark源码剖析
Spark是一个当下很火的集群计算平台,来自于加州大学伯克利分校的AMPLab,目前从Apache孵化器毕业,成为了Apache基金会下的顶级项目。现在的spark类似于hadoop,逐渐成长为一种生态系统。如下图所示,其上层包含了一系列计算工具,包括:
- Shark for SQL,查询hadoop数据的分布式SQL查询引擎,类似于hadoop上的hive,但效率更高。
- Streaming,利用spark来进行大规模流式数据处理。
- MLlib,基于spark的机器学习库。
- Graphx,spark之上的图计算框架,支持Pregel和GraphLab的计算模型。
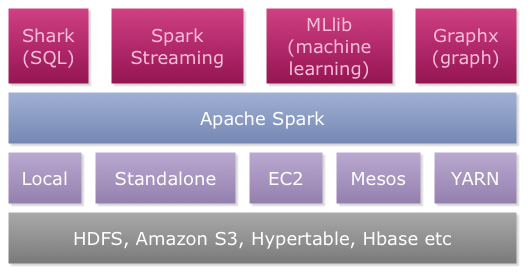
从spark创建之初,其对hadoop的支持就相当充分,当然一部分原因来自于Scala语言和Java语言交互的便利性。由上图可以看出,spark支持从HDFS等读出数据。尽管最开始,spark最先支持的是mesos(一个统一资源管理和调度平台),但在hadoop Yarn推出之后亦能很好地支持。除此之外,Spark能以本地多线程方式运行(local模式),也能以脱离mesos和Yarn的方式运行(standalone模式)。
Spark发展地如火如荼,尽管对于正常使用来说,我们不需要了解其内部的实现。但是要想深入优化上层应用,对底层的实现的了解是在所难免的。但是由于Scala语言的障碍,要想学习Spark需要从scala开始,学习曲线未免长了点。好在豆瓣的同学实现了一个spark的Python克隆:Dpark,其完全用Python语言翻译了spark。经过一段时间的研究,我对dpark的源码也有了一定程度的了解,因此就想写个系列来介绍其运行的原理。
然而Dpark有着不少的缺陷,下面就一一列举:
- 由于dpark翻译的时间较早(应该是spark 0.5前的版本,而spark目前最新版本已经是0.9),支持已经非常陈旧了。尽管dpark中RDD(spark中重要概念,表示弹性分布式数据集)还是内存层面上的抽象,而spark中的RDD是对内存和磁盘的统一抽象,另外缺少了上层的计算工具,但是其整体的思想是没有什么变化的。
- 对Hadoop的支持非常糟糕,dpark不支持从HDFS读取数据,取代支持的为分布式文件系统MooseFS;另外也不支持Yarn,当然还是支持mesos来进行调度的。
- 社区滞后,dpark目前的资料匮乏,开发也仅限于豆瓣的同学,没有来自社区的力量。spark则正好相反,社区的发展日益蓬勃,从底层到上层都有来自社区的大量贡献。
- GIL的限制,dpark中用多进程取代了spark中的多线程。
- 性能不佳,根据豆瓣的官方资料,dpark的性能甚至不如hadoop,这点让我比较吃惊。看来Python语言的性能劣势抵消了架构上带来的好处。
这些缺陷不能说dpark没有意义,其还是很好的学习工具。本来我研究dpark的初衷,是想完善其对Hadoop的支持,并移植spark graphx到dpark上。现在我更倾向于回归spark中,但是通过对dpark的研究,上手spark应该也更加容易。
Spark经过这么多版本的迭代,基本思想没有太大变化。我希望通过这个系列,能让大家能更容易地了解dpark/spark。本文也会作为系列的索引,并随着系列的进展而更新。
